Careful!
You are browsing documentation for a version of Kuma that is not the latest release.
Looking for even older versions? Learn more.
Overview
As we have already learned, Kuma is a universal control plane that can run across both modern environments like Kubernetes and more traditional VM-based ones.
The first step is obviously to download and install Kuma on the platform of your choice. Different distributions will present different installation instructions that follow the best practices for the platform you have selected.
Regardless of what platform you decide to use, the fundamental behavior of Kuma at runtime will not change across different distributions. These fundamentals are important to explore in order to understand what Kuma is and how it works.
Installing Kuma on Kubernetes is fully automated, while installing Kuma on Linux requires the user to run the Kuma executables. Both ways are very simple, and can be explored from the installation page.
There are two main components of Kuma that are very important to understand:
- Control Plane: Kuma is first and foremost a control-plane that will accept user input (you are the user) in order to create and configure Policies like Service Meshes, and in order to add services and configure their behavior within the Meshes you have created.
- Data Plane Proxy: Kuma also bundles a data plane proxy implementation based on top of Envoy. An instance of the data plane proxy runs alongside every instance of our services (or on every Kubernetes Pod as a sidecar container). This instance processes both incoming and outgoing requests for the service.
Multi-Mesh: Kuma ships with multi-tenancy support since day one. This means you can create and configure multiple isolated Service Meshes from one control-plane. By doing so we lower the complexity and the operational cost of supporting multiple meshes. Explore Kuma’s Policies.
Since Kuma bundles a data-plane in addition to the control-plane, we decided to call the executables kuma-cp and kuma-dp to differentiate them. Let’s take a look at all the executables that ship with Kuma:
kuma-cp: this is the main Kuma executable that runs the control plane (CP).kuma-dp: this is the Kuma data-plane executable that - under the hood - invokesenvoy.envoy: this is the Envoy executable that we bundle for convenience into the archive.kumactl: this is the the user CLI to interact with Kuma (kuma-cp) and its data.kuma-prometheus-sd: this is a helper tool that enables native integration between Kuma andPrometheus. Thanks to it,Prometheuswill be able to automatically find all dataplanes in your Mesh and scrape metrics out of them.kuma-tcp-echo: this is a sample application that echos back the requests we are making, used for demo purposes.
A minimal Kuma deployment involves one or more instances of the control-plane (kuma-cp), and one or more instances of the data-planes (kuma-dp) which will connect to the control-plane as soon as they startup. Kuma supports two modes:
universal: when it’s being installed on a Linux compatible machine like MacOS, Virtual Machine or Bare Metal. This also includes those instances where Kuma is being installed on a Linux base machine (ie, a Docker image).kubernetes: when it’s being deployed - well - on Kubernetes.
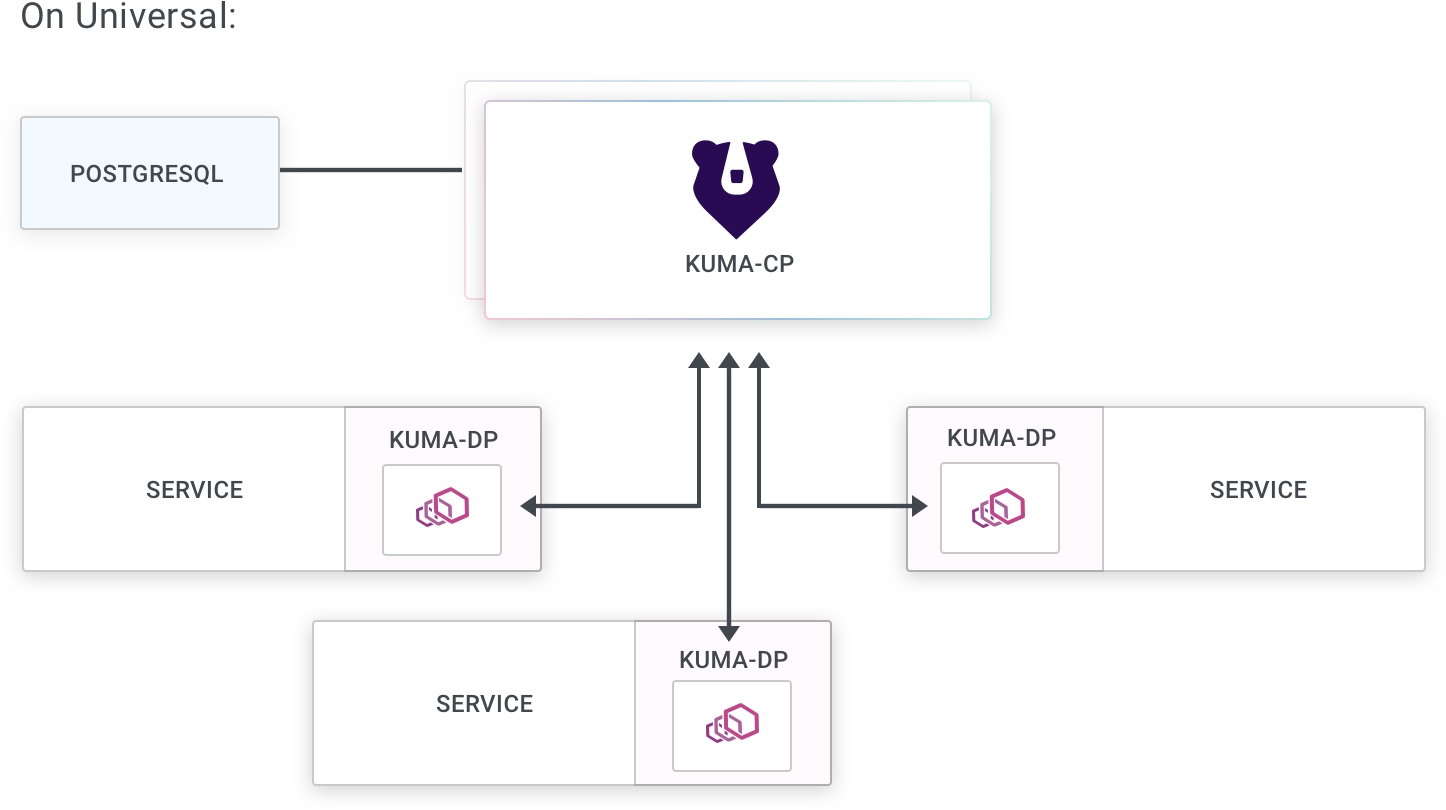
Universal mode
When running in Universal mode, Kuma will require a PostgreSQL database to store its state. The PostgreSQL database and schema will have to be initialized accordingly to the installation instructions:
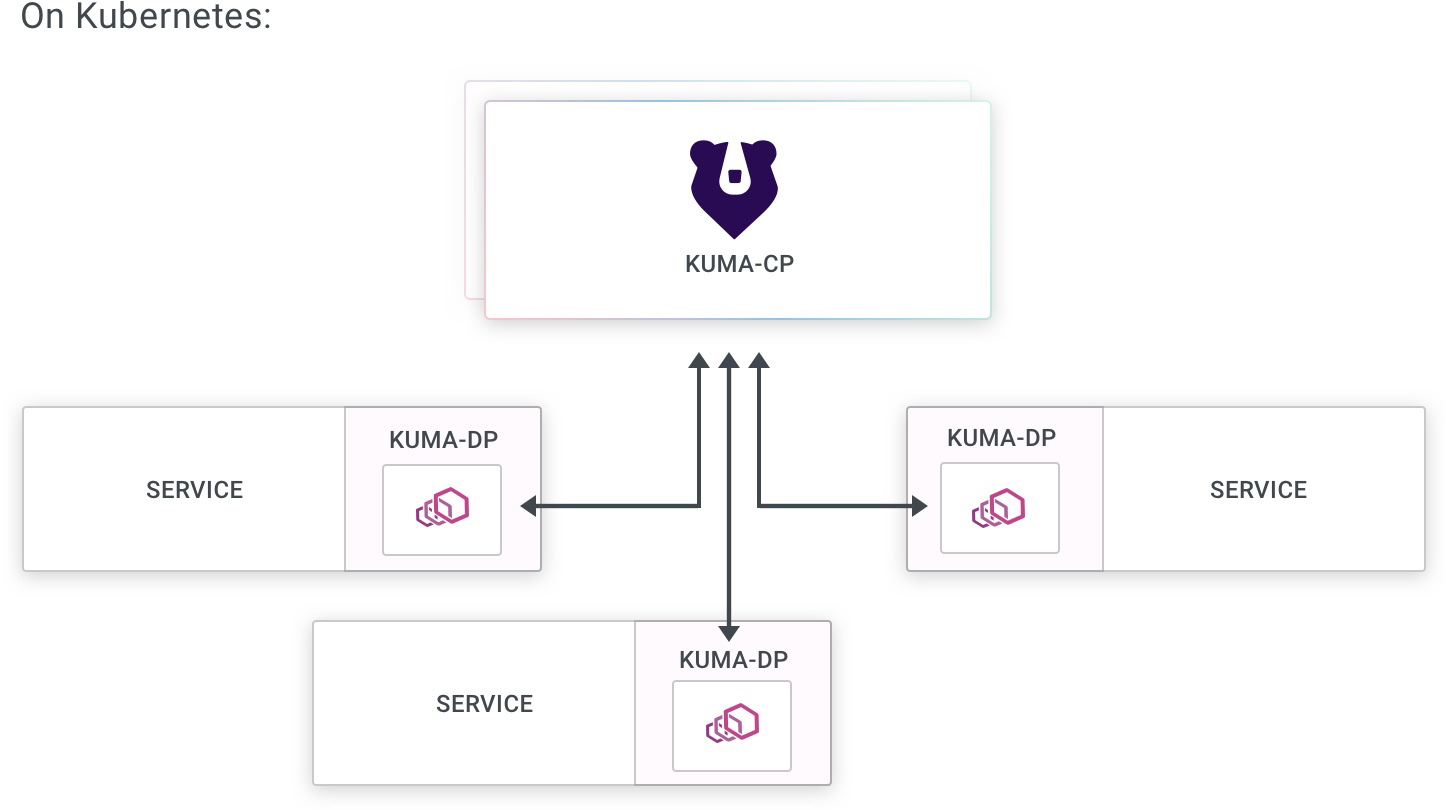
Kubernetes mode
When running on Kubernetes, Kuma will store all of its state and configuration on the underlying Kubernetes API Server, therefore requiring no dependency to store the data. Kuma will automatically inject the dataplane proxy kuma-dp on any Pod that belongs to a Namespace that includes the following annotation:
kuma.io/sidecar-injection: enabled
You can learn more about sidecar injection in the section on Dataplanes.
Specify Mesh for Pods
When deploying services in Kubernetes, you can determine which Mesh you want the service to be in by using the kuma.io/mesh: $MESH_NAME annotation. This annotation would be applied to a deployment like so:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
namespace: kuma-example
spec:
...
template:
metadata:
...
annotations:
# indicate to Kuma that this Pod will be in a mesh called 'new-mesh'
kuma.io/mesh: new-mesh
spec:
containers:
...
This kuma.io/mesh annotation also could be set on the namespace. In this case all Pods in the namespace belong to specified mesh.
See also a complete list of the annotations you can specify in Kubernetes mode.
Matching Labels in Pod and Service
In a typical Kubernetes deployment scenario, every Pod is part of at least one matching Service. For example, in Kuma’s demo application, the Pod for the Redis service has the following matchLabels:
...
spec:
selector:
matchLabels:
app: redis
role: master
tier: backend
...
At least one of these labels must match the labels we define in our Service. The correct way to define the corresponding Redis Service would be as follows:
kind: Service
metadata:
name: redis
namespace: kuma-demo
labels:
app: redis
role: master
tier: backend
Full CRD support: When using Kuma in Kubernetes mode you can create Policies with Kuma’s CRDs applied via kubectl.
Service pods and service-less pods
In some cases, there might be a need to have Pods which are part of the mesh, yet they do not expose any services themselves. These are typically various containerised utilities, Kubernetes jobs etc. Such Pods are not bound to a Kubernetes Service as they would not have any ports exposed.
Pods with a Service
For all Pods associated with a Kubernetes Service resource, Kuma control plane will automatically generate an annotation kuma.io/service: <name>_<namespace>_svc_<port> fetching <name>, <namespace> and <port> from the that service. For example, the following resources will generate a dataplane tag
kuma.io/service: echo-server_kuma-test_svc_80:
apiVersion: v1
kind: Service
metadata:
name: echo-server
namespace: kuma-test
annotations:
80.service.kuma.io/protocol: http
spec:
ports:
- port: 80
name: http
selector:
app: echo-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-server
namespace: kuma-test
labels:
app: echo-server
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: echo-server
template:
metadata:
labels:
app: echo-server
spec:
containers:
- name: echo-server
image: nginx
ports:
- containerPort: 80
Pods without a Service
When a pod is spawned without exposing a particular service, it may not be associated with any Kubernetes Service resource. In that case, Kuma control plane will generate kuma.io/service: <name>_<namespace>_svc, where <name> and<namespace> are extracted from the Pod resource itself omitting the port. The following resource will generate a dataplane tag
kuma.io/service: example-client_kuma-example_svc:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-client
labels:
app: echo-client
spec:
selector:
matchLabels:
app: echo-client
template:
metadata:
labels:
app: echo-client
spec:
containers:
- name: alpine
image: "alpine"
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "tail -f /dev/null"]
In both cases these tags will be see in the CLI and GUI tools when inspecting the particular Pod dataplane.
Last but not least
Once the kuma-cp process is started, it waits for data-planes to connect, while at the same time accepting user-defined configuration to start creating Service Meshes and configuring the behavior of those meshes via Kuma Policies.
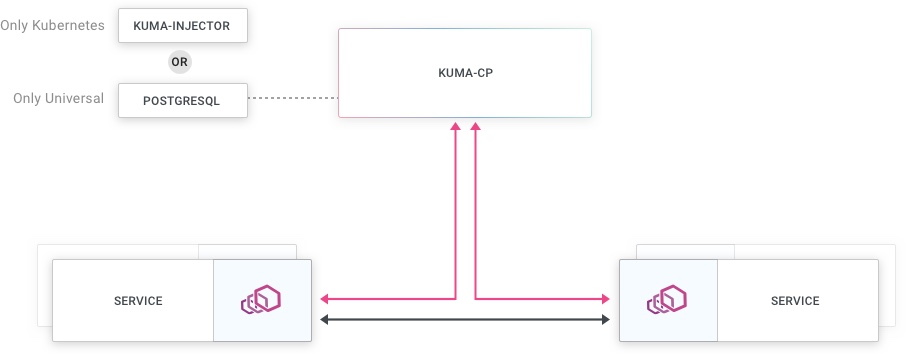
When we look at a typical Kuma installation, at a higher level it works like this:
When we unpack the underlying behavior, it looks like this:
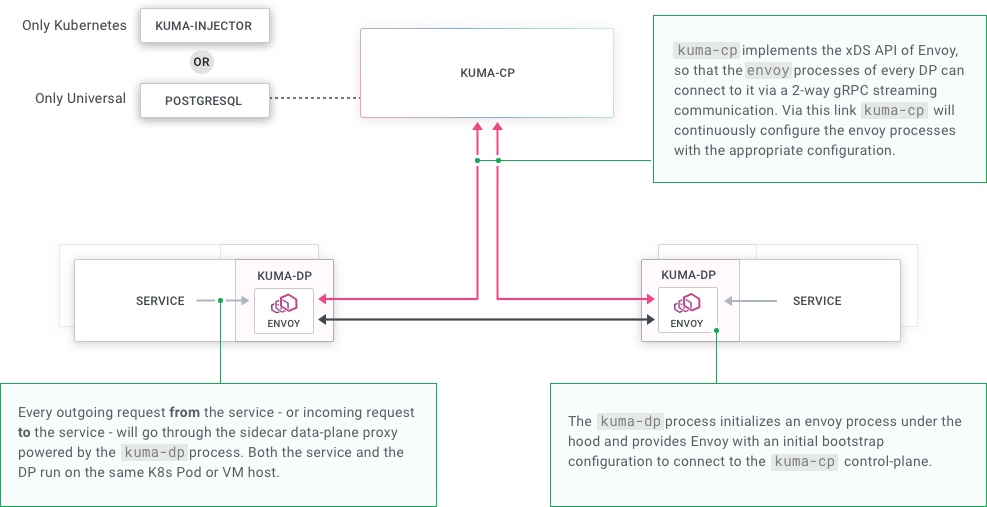
xDS APIs: Kuma implements the xDS APIs of Envoy in the kuma-cp application so that the Envoy DPs can connect to it and retrieve their configuration.